Q10058 Detecting trigger events in a pre-processed data stream
I take a signal from one of my input channels and "clean it up" for detecting events with software triggering. When I use the trigger events to capture data from my input channels, things quickly go chaotic, as if the signals and events do not correspond. What is happening?
You have basically explained it already. The signals and events do not correspond. The following diagram is typical of a processing configuration having problems of this sort.
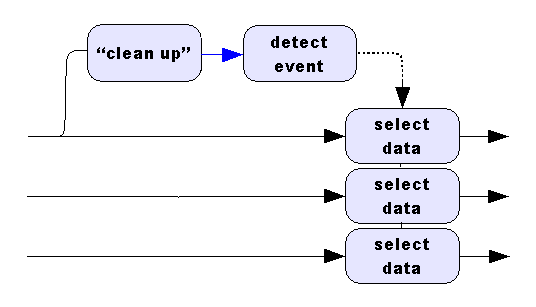
The processing labelled as "clean up" in the diagram has several ways that it could introduce problems:
- delaying the apparent location of events (filtering)
- changing the data rates (decimation or reduction)
- removal of data from the original data stream (selection or skipping)
To avoid steep costs in performance and complexity, the DAPL system does not attempt to tag each sample according to a relative position in a real time sequence. Instead, the DAPL system identifies relevant data or events by indexing to a sample position within the analyzed data stream. You can use these timestamp index values to access data in any other data stream, provided that there is a one-for-one relationship between sample positions in the streams. If the locations in the streams you analyze and the streams you take data from do not correspond, this causes problems. You can avoid these problems by:
- starting with data streams having samples that correspond one-to-one, typically multiple channels from the same input sampling configuration
- discarding data from all signal streams at the same places and in the same amounts
- maintaining the one-to-one correspondence in all data reductions
Filter pre-processing tends to time-shift data, while actions such as averaging, software triggering or data skipping select samples and reduce the data rate. If you equivalently time shift, select, or modify the data rates of the other channels to preserve alignment, you can use the trigger events to access the aligned data streams, as illustrated in the following diagram.
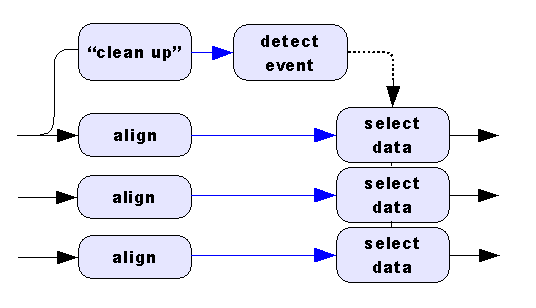
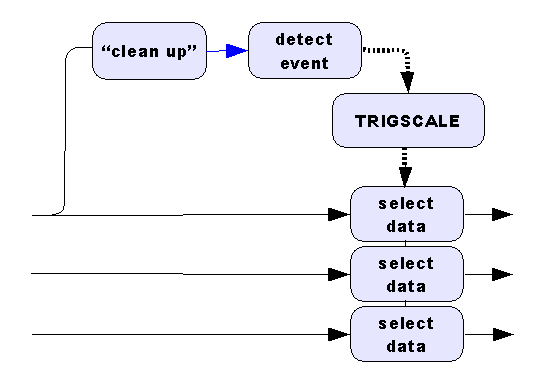
A second strategy is to correct for known differences between
positions in the analyzed data stream and the other data streams. This
works best when there is a simple integer multiplier between the data
rates in the two streams. A classic example is the problem: "Retain a
block of 100 points if the average value within the block is
positive." When you average blocks of 100 values for the
triggering analysis, this automatically reduces the data rate to 1/100 of
the previous rate. You can correct for the known differences between the
two data rates using the TRIGSCALE processing command,
as illustrated in the following diagram.
L24076
Software triggering principles are summarized and discussed
in detail in the Triggering chapter of the
DAPL 3000 Reference Manual.
Also look for details about the TRIGSCALE command there.
There is also an online tutorial
about software triggering with several application examples.